연구를 할때 데이터를 여러 소스에서 가져오는 경우가 많죠.
예를 들면 국가별 주가지수 수익률과 GDP성장률의 관계를 살펴보는 연구를 한다면
주가지수는 야후 finance에서, GDP는 World bank에서 가져올 수 있겠죠.
그럴때 두개의 데이터셋을 하나의 데이터셋으로 합치는 작업이 필요합니다.
오늘은 두 데이터셋을 합치는 데 쓸수있는 함수 merge와 concat에 대해서 다루어 보겠습니다.
판다스 라이브러리를 사용하겠습니다.
0. 데이터 준비
import pandas as pd
import pandas as pd 로 판다스를 불러오면서 시작할게요.
(판다스 설치가 안되어있다면 pip install pandas 를 이용해서 설치해 주세요.)
예시로 데이터셋 두개를 만들어볼건데요,
첫번째 데이터 프레임에는 계절별 스포츠 경기 관객수가 있고,
두번째 데이터 프레임에는 계절별 스포츠경기 티켓 가격이 있다고 해볼게요
df_fans=pd.DataFrame({'season':['summer', 'fall', 'winter'],'fans_soccer': [20,50,10], 'fans_skiing': [0,0,20]})
df_price=pd.DataFrame({'season':['spring', 'summer', 'winter'], 'price_soccer': [15,15,20], 'price_skiing':[40,40,10]})
만들어진 데이터는 이렇게 생겼습니다.
(참고: 저는 Jupyter Notebook을 사용하고 있어요.)

첫번쨰 데이터에는 여름,가을,겨울만 있고
두번째 데이터에는 봄,여름,겨울만 있다는걸 기억해주세요.
1. pd.merge
이제 두 데이터 프레임을 merge구문을 이용해서 합쳐보겠습니다.
merge는 엑셀로 생각하면 vlookup으로 생각할수 있을 것 같아요.
양쪽 데이터 프레임이 공통적으로 가지고있는 특정 칼럼을 기준으로 두개의 데이터 프레임을 합치는 데 사용합니다.
pd.merge 함수에서 가장 핵심적인 argument는 4개입니다.
syntax: pd.merge( left, right, on, how)
- left와 right는 합치려는 데이터프레임1과 데이터프레임2입니다. → 위의 예시에서는 df_fans, df_price에 해당합니다.
- on : 데이터를 합치는 기준이 되는 칼럼입니다. 양쪽 데이터 프레임 모두에 있는 칼럼이어야 합니다.
저는 계절별 관람객수와 계절별 티켓 가격을 하나의 데이터로 합치고 싶기때문에 계절이 데이터를 합치는 기준 칼럼이 됩니다. → on='season' - how는 merge 방식인데요,
left 데이터프레임과 right 데이터프레임의 기준 칼럼(on으로 지정해주는)에 포함되어있는 관측치가 서로 다를 경우
무엇을 기준으로 최종파일을 완성할지를 지시하기 위한 argument입니다.- how의 값으로는 left, right, outer, inner가 주로 쓰입니다.
아래 그림에서 각각의 값을 사용했을때 결과의 차이를 확인해보세요. - how=left일 경우 left 데이터프레임 기준이므로 여름,가을,겨울 데이터가 결과 df 에 남게됩니다. right 데이터프레임에는 가을이 없으므로 price 값들은 season=가을인 행에 대해 nan 값이 붙게 됩니다.
- 반대로 how=right일 때는 right 데이터프레임에 있는 봄,여름,겨울이 결과 df에 남게됩니다.
- how=outer는 left df와 right df의 season column의 합집합을 구합니다.
- how=inner는 교집합만 최종 df에 남깁니다.
- how의 값으로는 left, right, outer, inner가 주로 쓰입니다.

on으로 여러개의 칼럼을 지정해도 됩니다.
여러개의 칼럼을 기준으로 merge하는 방법에 대해서 예시를 들기 위해서, 아래 두개 데이터 셋을 볼게요.
- 위에서 만든 데이터 프레임 두개를 좀 변형했습니다. pd.wide_to_long 을 사용합니다.
현재 df_fans와 df_price는 wide format이라고 할 수 있는데요, 이걸 long format으로 바꾸어보겠습니다.
(데이터의 wide format은 여러 대상(예시에서는 스포츠 종류)에 대한 하나의 변수(예시에서는 관객수)값이 개별 칼럼으로 옆으로 길게(wide하게) 붙어있는 경우를 의미합니다.
반대로 long format은 칼럼으로 변수 하나만 있고, 여러 대상에 대한 값이 행으로 아래쪽으로 길게(long) 붙어있는 경우예요.)
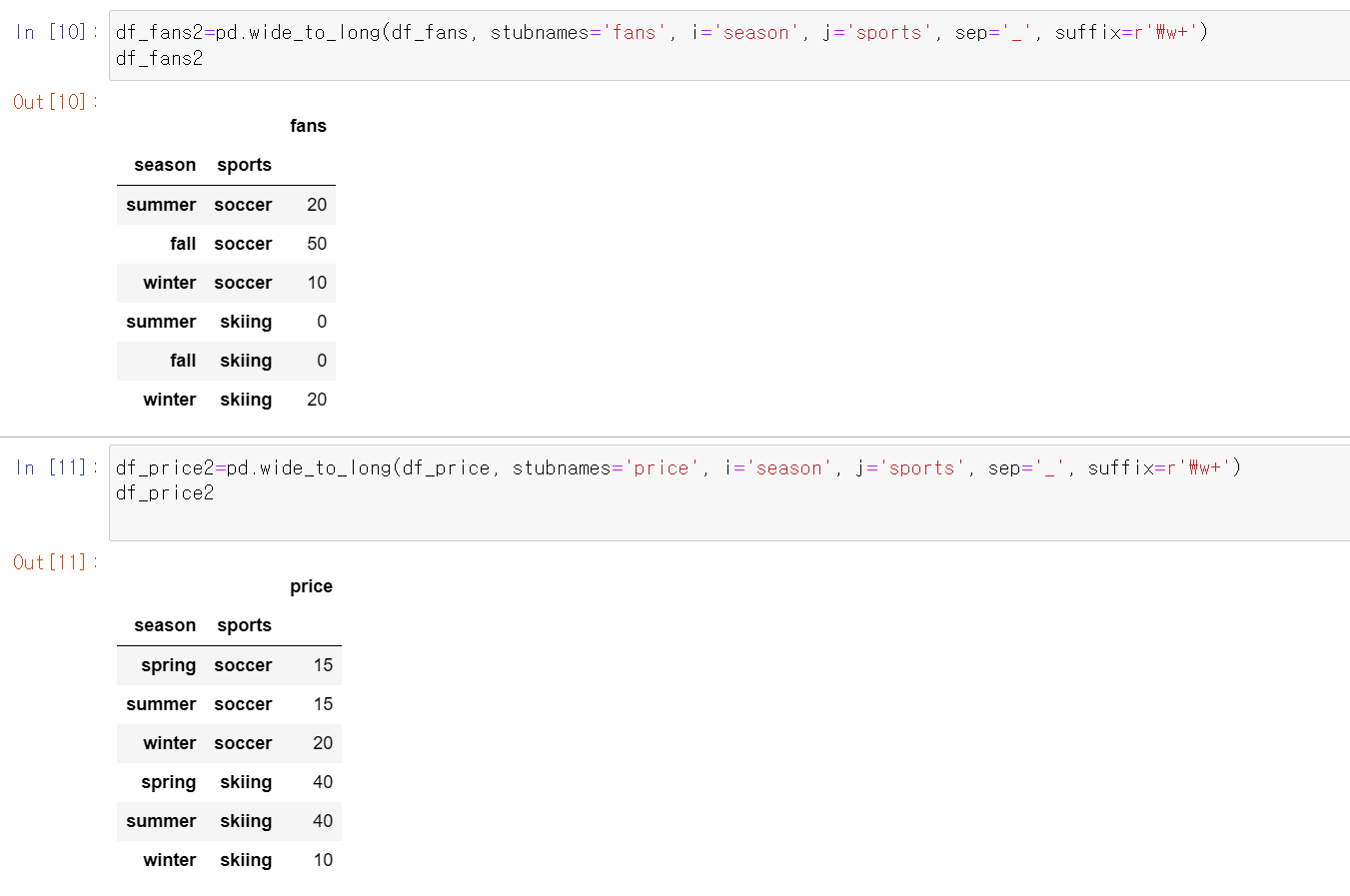
- (wide_to_long 사용할때 헷갈리기 쉬운 부분: suffix를 r'\w+' 로 지정해는 것은 j의 값이 스트링임을 표시하는겁니다.)
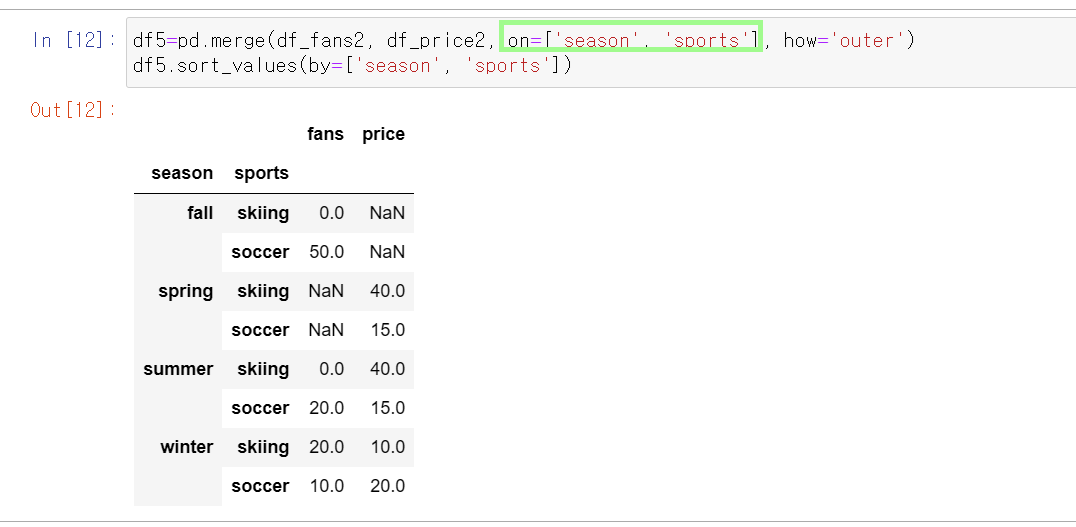
- 이 두 파일을 이제 merge를 이용해서 붙여볼게요. 여러개의 칼럼을 기준으로 merge할때는 on argument의 값을 리스트로 넣어줍니다:
2. pd.concat
merge는 서로 다른 칼럼들을 가지고 있는 데이터 프레임을 양쪽에 모두 포함되어있는 특정 칼럼을 기준으로 결합하는 것이었다면, concat은 서로 다른 행(관측치)을 가지고 있는 데이터셋들을 아래 위로 길게 붙일 때 주로 사용합니다.
(STATA로 생각하면 append 용도)
예를 들어, 제가 가장 많이 concat을 사용하는 경우는 데이터 프레임이 년도별로 나뉘어져 있을 때입니다.
아래와 같은 두가지 데이터 셋을 만들어보았어요.
df2003=pd.DataFrame({'yq':[200303,200306,200309,200312], 'price': [ 1, 1.5, 1.6, 2], 'fans': [100, 101, 100, 110]})
df2004=pd.DataFrame({'yq':[200403,200406,200409,200412], 'fans': [110, 115, 120, 125], 'price': [ 1.9, 2, 2.3, 2.6], 'teams': [10,11,12,13] })
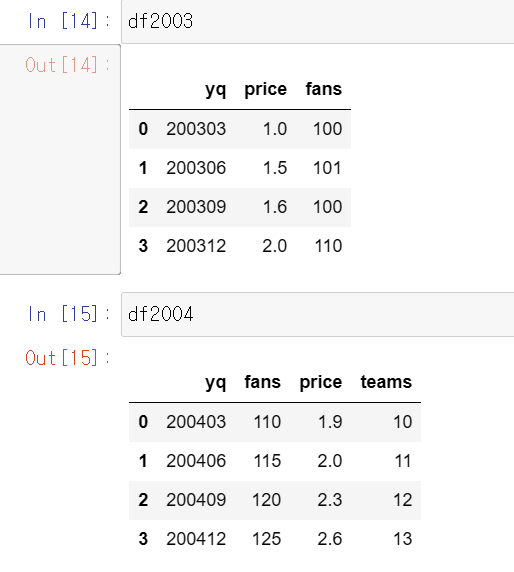
df2003에는 2003년의 야구경기 티켓가격과 관람객수 정보가 있고,
df2004에는 2004년의 관람객수, 티켓 가격, 토너먼트에 참가한 팀 수가 적혀있다고 합시다.
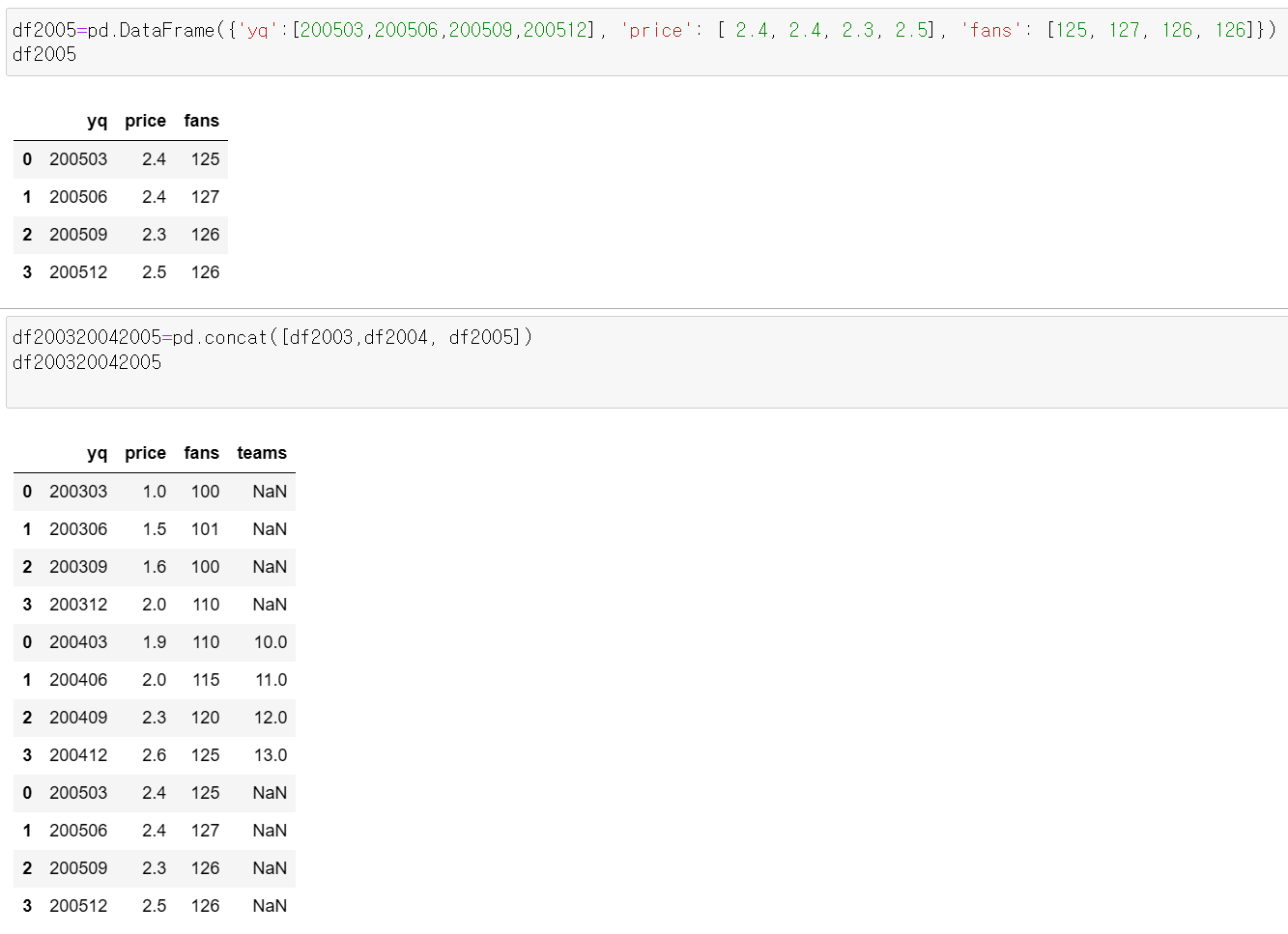
pd.concat을 이용하면 두 데이터프레임을 아래위로 연결해서 price와 fans의 시계열을 길게 이어붙일 수 있습니다.

concat은 이렇게 간단하게 쓸수 있는데요,
이때 주의하실점은 concat의 argument로 데이터 프레임 이름들을 넣을때 리스트 형태로 넣어줘야 한다는 겁니다.
리스트 형태로 넣으니 당연히 두개 이상을 한꺼번에 붙이는 것도 가능합니다.
이번 포스팅에서는 pd.merge와 pd.concat에 대해 다루었어요.




