파이썬을 이용한 패널데이터 분석 3번째 포스팅입니다.
지금까지의 파이썬 포스팅은 여기에:
https://log-maynard.tistory.com/9
[Python] 파이썬을 이용한 패널 데이터 분석 - Pandas dataframe에서 전기항(전기값) 변수 만들기, lag oper
패널 데이터 분석(혹은 시계열 데이터 분석)을 하다보면 변수의 전기값을 값으로 갖는 변수를 만들어야 할 때가 있습니다. 예를들면, 성장률(증가율)을 계산하려면 전기항을 불러와서 이번기값/
log-maynard.tistory.com
https://log-maynard.tistory.com/16
[Python] STATA와 Python 비교. STATA에서 Python으로 옮겨가기: 기본기능 비교 - Part1
요즘 Python이 워낙 많이 쓰이다 보니 STATA나 SAS, R 등을 쓰다가도 Python으로 옮겨가는 분들이 많은 것 같습니다. Python은 범용언어이기 때문에 유연하게 여러가지 목적으로 사용하기에
log-maynard.tistory.com
https://log-maynard.tistory.com/24
[Python] 파이썬을 이용한 패널 데이터 분석 2 - 여러 데이터 셋 합치기, 판다스 pd.merge와 pd.concat, 파
연구를 할때 데이터를 여러 소스에서 가져오는 경우가 많죠. 예를 들면 국가별 주가지수 수익률과 GDP성장률의 관계를 살펴보는 연구를 한다면 주가지수는 야후 finance에서, GDP는 World bank에서
log-maynard.tistory.com
Pandas dataframe은 칼럼과 행으로 구성되어있는데요, 그래서 패널데이터 분석에 많이 사용됩니다.
그런데, 입수한 패널 데이터 셋에 포함된 칼럼과 행의 숫자가 너무 많을때 필요한 칼럼 또는 행만 필터링 해내는 방법이 있습니다. STATA의 keep 또는 drop 기능이나 MS 엑셀의 필터 기능과 비교할 수 있어요.
오늘은 pandas dataframe에 적용할 수 있는 filter 매소드를 이용해서 특정 형식을 갖춘 칼럼 또는 행을 골라내는 방법을 다루겠습니다:
<요약>
1. 칼럼 이름 또는 행 index가 특정문자와 일치하는 경우만 가져오기: regex='^문자열$', item=['문자열']
2. 칼럼 이름 또는 행 index가 특정문자로 시작하는 경우 가져오기: regex= '^문자열'
3. 칼럼 이름 또는 행 index가 특정문자로 끝나는 경우 가져오기: regex = '문자열$'
4. 칼럼 이름 또는 행 index가 특정문자를 포함하는 경우 가져오기: regex='문자열', like='문자열'
0. 데이터 준비:
예시를 들기위해 데이터 프레임을 먼저 만들었습니다.
(정규표현식 설명을 위해 만든 가상의 데이터라 내용 자체에 의미는 없고, 굳이 의미를 부여해보자면 각 학교에서 동물원에 방문한 날짜와 각 동물원에 살고있던 동물 나이라고 해볼게요. 그리고 방문한 학생 수도 있습니다. ㅎㅎ)
import pandas as pd
import numpy as np
data = {
'school_name': ['A', 'B', 'C'],
'cat_age': [1, 2, 1],
'dog_age': [4, 5, 5],
'student_count': [30, 45, 60],
'age_tiger': [15,5,np.nan]
}
df = pd.DataFrame(data, index=['March2003', 'May2004', 'June2003'])

1. 칼럼 이름 또는 행 index가 특정문자와 일치하는 경우만 가져오기
1) 칼럼을 선택하기
syntax: df.filter(regex='^칼럼명에 해당하는 문자열$')
데이터프레임이름.filter를 하신 후에 정규표현식을 의미하는 regex를 써주고 뒤에 가져오려는 칼럼명을 ^와 $사이에 쓰면 해당 칼럼을 가져옵니다. 예를들면,

여기에서,
^는 칼럼명이 해당 문자열로 시작됨을 의미하고 (즉, 앞에 다른 문자가 없음)
$는 칼럼명이 해당 문자열로 끝남을 의미합니다 (즉, 뒤에 다른 문자가 없음).
2) 행을 선택하기
syntax: df.filter(regex='^index에 해당하는 문자열$', axis=0)
인덱스를 이용해서 행을 필터링 해낼 수도 있습니다. 방법은 동일하기 regex에 ^인덱스에 해당하는 문자열$ 을 넣어주면 되고, 이때 주의할 점은 axis=0으로 설정해주는 겁니다.
파이썬에서 axis=0은 행, axis=1은 칼럼을 의미하고,
filter() 매소드가 데이터 프레임에 적용될때 axis argument의 디폴트 값은 1로 설정되어 있습니다. 그래서 칼럼 필터링을 할때는 axis를 따로 명시해주지 않아도 됩니다.
3) df.filter(item=['칼럼명']) 과 동일한 결과
df.filter 안에 regex='^칼럼명$' 으로 지정해주어 특정 칼럼을 발라내는 것과 item=['칼럼명']으로 써주는 것은 같은 결과를 가져옵니다.
- 아래 그림에서와 같이 item은 리스트를 input값으로 받기 때문에 칼럼을 여러개 동시에 가져오는 것도 가능합니다.
- 그리고 행을 가져오기 위해서는 마지막에 axis=0을 추가해주세요.


2. 칼럼 이름 또는 행 index가 특정문자로 시작하는 경우 가져오기
1) 컬럼을 선택하기
syntax: df.filter(regex='^문자열')
위에서 언급했듯이 regex 표현에서 ^는 주어진 문자열로 시작함을 의미합니다.
따라서 특정 문자열로 시작하는 칼럼만 필터링해내고 싶을떄는 regex에 ^뒤에 원하는 문자열을 넣어주시면 됩니다.
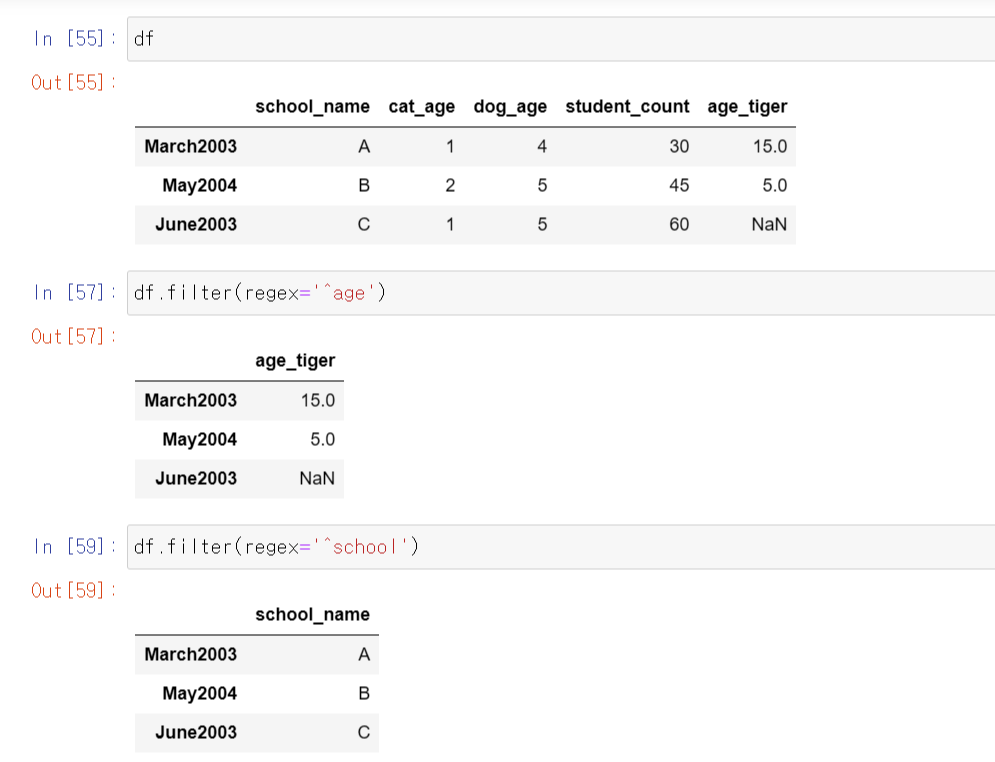
2) 행을 선택하기: axis argument를 0으로 설정해주세요.
syntax: df.filter(regex='^문자열', axis=0)

3. 칼럼 이름 또는 행 index가 특정문자로 끝나는 경우 가져오기
1) 칼럼을 선택하기
syntax: df.filter(regex='문자열$')
문자열 앞에 ^를 붙이면 해당 문자열로 시작한다는 의미이고,
문자열 뒤에 $를 붙이면 해당 문자열로 끝난다는 의미입니다.
따라서 regex='문자열$' 로 지정해주면 해당 문자열로 끝나는 칼럼들만 필터링할 수 있어요.
2) 행 선택하기: 앞에서와 마찬가지로 axis=0을 추가.
syntax: df.filter(regex='문자열$', axis=0)

4. 칼럼 이름 또는 행 index가 특정문자를 포함하는 경우 가져오기
syntax:
df.filter(like='문자열') 또는 df.filter(regex='문자열')
df.filter(like='문자열', axis=0) 또는 df.filter(regex='문자열', axis=0)
특정 문자열이 포함된 칼럼을 가져오려면 regex를 사용할 수도 있고 like를 사용할 수도 있어요.

걸러내고자 하는 문자열을 여러개 지정할 수도 있습니다.
만약 age 또는 count라는 문자열을 포함하는 칼럼들을 선택하고 싶다면 | 을 사용하면 됩니다.
정규표현식에서 | 표시는 '또는' 을 의미합니다.
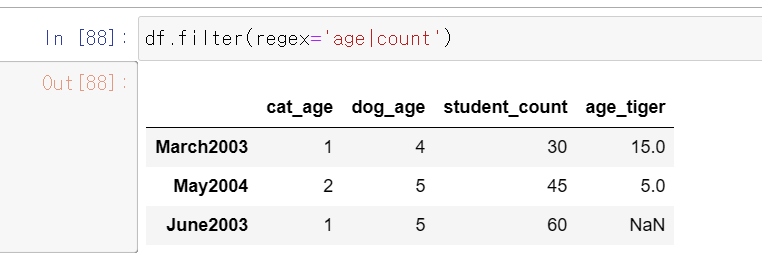
조금 더 응용을 해서 age로 끝나거나 count를 포함하는 칼럼을 찾을 수도 있어요.
regex='age$|count'

여기에서 한가지 눈여겨 볼 것은 | 앞뒤로 들어간 정규표현식이 구분되어있다는 거에요.
regex='^age|count' 와 regex='^age|^count' 의 결과를 비교해보면 쉽게 알 수 있습니다.
regex='^age|count' 에서 | 앞의 ^는 age에만 영향을 미치고 count에 적용되지는 않기 때문에 age로 시작하거나 count를 포함하는 칼럼들을 가져옵니다.
한편 두번째 표현처럼 ^age|^count를 써주면 age와 count 양쪽에 ^가 표현되기 때문에 age로 시작하는 age_tiger 칼럼을 가져옵니다. count로 시작하는 칼럼은 없기 때문에 이 표현에 해당되는 칼럼은 가져오지 못합니다.

Note: filter의 argument에 대해 좀더 자세히 알고싶다면 아래 링크를 확인하세요.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.filter.html
pandas.DataFrame.filter — pandas 2.2.2 documentation
The axis to filter on, expressed either as an index (int) or axis name (str). By default this is the info axis, ‘columns’ for DataFrame. For Series this parameter is unused and defaults to None.
pandas.pydata.org
오늘은 간단한 표현들만 다루었는데요, 정규표현식은 여기저기 쓰임새가 많아서 익혀두면 도움이 많이 될것 같아요.




