요즘 Python이 워낙 많이 쓰이다 보니 STATA나 SAS, R 등을 쓰다가도 Python으로 옮겨가는 분들이 많은 것 같습니다.
Python은 범용언어이기 때문에 유연하게 여러가지 목적으로 사용하기에 아주 좋습니다.
오늘은 STATA에서 Python으로 옮겨가는 분들, 혹은 Python을 다루지만 STATA도 좀 알고싶은 분들을 위해서
둘을 비교해보려고 합니다. 특히 이번 포스팅에서는 Python Pandas 라이브러리 위주로 STATA와 비교해보겠습니다. STATA의 데이터 셋과 판다스의 데이터 프레임을 대응시킬 수 있기 때문입니다.
내용이 좀 길것 같아서 포스팅을 여러 파트로 나누어서 다루려고 합니다.
오늘 다룰 내용은 아래와 같습니다.:
1. import
2. 변수 rename
3. destring
4. 연산
파이썬이 익숙하신 분들에게는 다소 길고 부연설명이 많은 포스팅이 될 수 있으니 코드 블럭 또는 그림 위주로 살펴보셔도 좋습니다.
먼저 이번 포스팅에서 사용할 데이터는 세인트루이스 Fed의 거시경제 데이터 입니다.
미시건 대학교의 Consumer sentiment 지수와 산업생산지수를 사용해보겠습니다.
출처와 변수명은 다음과 같습니다.
https://fred.stlouisfed.org/
- University of Michigan: Consumer Sentiment (UMCSENT)
- Industrial Production: Total Index (INDPRO)
다운 받은 파일은 이런 모습입니다.

1. import
먼저 데이터 불러오기 입니다.
#STATA: import delimited fredgraph.csv
#Python:
import pandas as pd
df = pd.read_csv("fredgraph.csv")
STATA에서는 파일을 불러올 때 import delimited(csv 또는 txt 파일) 혹은 import excel 구문을 사용하는데요,
파이썬에서는 pandas 라이브러리를 이용합니다.
pandas를 pd라는 이름으로 불러온 후 read_csv 코드를 사용해주면 됩니다. 엑셀을 불러올 때는 pd.read_excel 해주세요.
[예시] St.Louis Fed에서 다운받아 저장한 파일을 아래와 같이 불러왔습니다. 파일 이름은 "fredgraph.csv"입니다. 파이썬에서 불러온 객체는 df라는 이름으로 저장했습니다.

2. 변수 rename
#STATA: rename UMCSENT consumer_sentiment
#STATA: rename INDPRO industrial_production
#Python:
df=df.rename(column={'UMCSENT':'consumer_sentiment', 'INDPRO': 'industrial_production'})
STATA에서는 rename 원래변수명 새변수명 의 문법을 사용하는 반면,
Python에서는 dataframe이름.rename() 매소드를 사용합니다. 괄호 안에는 원래 변수명과 새 변수명을 딕셔너리 형태로 넣어주면 됩니다.
[예시] import한 데이터에서 변수명이 UMCSENT INDPRO 로 줄여져 있으니 알아보기 쉽도록 풀어 써주겠습니다.
UMCSENT는 consumer_sentiment로, INDPRO는 industrial_production으로 이름을 바꾸어줍니다.
주피터 노트북에서 데이터프레임 객체이름을 치면 그 내용을 보여주는데요, 아래 그림에서 df 라고 쳐서 내용을 확인해보면 변수명이 바뀐 것을 확인할 수 있습니다.

3. destring
#STATA: destring industrial_production, replace
#Python:
df['industrial_production']=[float(x) for x in df['industrial_production']]
데이터 파일을 import 해올 때 숫자가 문자로 인식되는 경우가 있습니다. 그럴 때 문자를 숫자로 바꿔주기 위해,
STATA에서는 destring 구문을 사용합니다. destring 변수명, replace
Python에서는 조금 더 코드가 복잡한데요, 원하는 변수의 칼럼을 df['칼럼명']을 통해 지정해주고, 해당 칼럼을 list comprehension을 이용해 바꾸어 줍니다. 아래 예시를 통해 좀 더 자세히 얘기해보겠습니다.
[예시]
(1) 아래 그림에서 두번째 줄 type(df['consumer_sentiment'][0]) 은 df라는 데이터프레임의 consumer_sentiment 칼럼의 [0]번 index 관측치의 자료형(type)을 알려달라는 코드입니다.
(Note: 파이썬에서 index는 0,1,2,3,... 순서로 나아가므로, 0번째 index의 관측치는 첫번째 관측치입니다. 위의 그림에서 79.133333에 해당합니다.)
아래 그림에는 나와있지 않지만 이 코드를 입력했을때 자료형이 string 이라는 답을 받았습니다.
(2) 그 다음줄에서 df['consumer_sentiment']= 이라고 적혀있는 부분은 df의 consumer_sentiment 칼럼을 등호(=) 뒤의 값으로 바꾼다는 뜻입니다. 등호 뒤에는 list comprehension 구문이 들어가있습니다.
[float(x) for x in df['consumer_sentiment']] 는 df의 consumer_sentiment 칼럼의 요소 x에 대해 x를 float 자료형으로 변형시켜서 리스트로 만들라는 것입니다.
(3) 이제 자료형이 바뀌었는지 확인해보기 위해 다시 type()을 이용하였습니다. 네번째 줄의 type(df['consumer_sentiment'][1]) 의 결과 반환된 값은 numpy.float64 입니다. 값이 성공적으로 숫자로 바뀌었습니다.
(2)번에서 consumer_sentiment 칼럼의 모든 요소(x)를 숫자로 변환했으므로 type(df['consumer_sentiment'][1]) 대신 type(df['consumer_sentiment'][0]) 또는 type(df['consumer_sentiment'][17]) 등을 써도 모두 float 라는 자료형으로 변경되었을 겁니다.

4. 연산
이제 변수의 값들이 숫자로 바뀌었으니 마음대로 연산을 하면 됩니다. 이번에는 consumer_sentiment와 industrial_production이 전기 대비 얼마나 증가하였는지 상승률을 계산해보겠습니다. 이를 위해 연산에 앞서 shift 메소드를 이용해서 전기 값을 불러와주겠습니다.
shift() 사용법에 대해서는 이 포스팅을 참고해주세요:
https://log-maynard.tistory.com/9

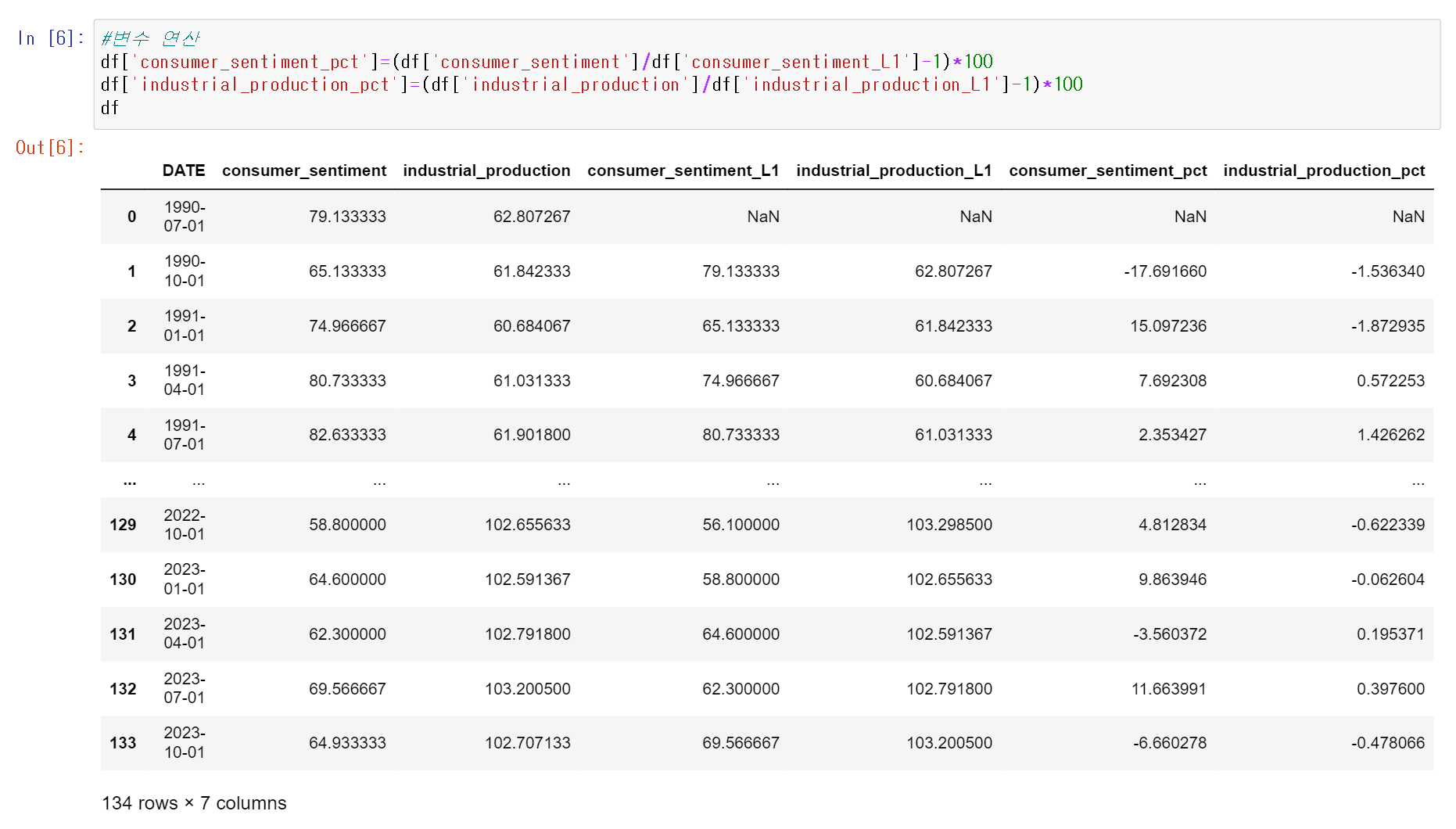
이제 연산입니다.
#STATA: gen consumer_sentiment_pct = (consumer_sentiment/consumer_sentiment_L1 - 1)*100
#Python:
df['consumer_sentiment_pct'] = (df['consumer_sentiment']/df['consumer_sentiment_L1']-1)*100
STATA에서는 gen 을 이용해 새로운 변수를 만들고 변수명을 이용해 연산을 해줍니다.
변수 A와 B를 더하려면 A+B, 나누려면 A/B 이런 식이죠.
Python에서도 연산은 유사한 방식으로 할수 있습니다.
[예시] 아래에서 결과를 확인해보면, 1990년 10월 1일 데이터의 consumer_sentiment의 전기 대비 증가율이
(65.133333/79.133333-1)*100=약 -17.692로 잘 계산된걸 확인할 수 있습니다. 덧셈, 뺄셈, 곱셈 등 다른 연산도 유사하게 할 수 있습니다.
오늘의 포스팅은 여기까지입니다.




