패널 데이터 분석(혹은 시계열 데이터 분석)을 하다보면 변수의 전기값을 값으로 갖는 변수를 만들어야 할 때가 있습니다. 예를들면, 성장률(증가율)을 계산하려면 전기항을 불러와서 이번기값/전기값-1= 증가율로 계산해줘야 합니다.
이번에는 판다스(pandas) library를 사용해서 데이터를 분석하는 세팅에서, 전기항 만드는 방법에 대해서 포스팅하려고 합니다.
구체적으로는 다음과 같은 것들에 대해서 다뤄보겠습니다:
0. (준비단계) 데이터 프레임 만들기
1. shift()
2. (응용) lag operator 만들기
3. (참고) pct_change

0. (준비단계) 데이터 프레임 만들기
먼저 아래 코드를 이용해서 주가 데이터를 데이터프레임에 입력해주겠습니다.

- pandas와 numpy 라이브러리를 불러와 줍니다.
- 딕셔너리 형태로 칼럼명과 칼럼값들(리스트)을 입력해 줍니다. 데이터 프레임 이름은 df로 하였습니다.
- 코드가 길어져서 \를 넣어서 (위의 그림에서는 원화 표시로 되어있네요) 코드를 다음줄로 넘겨주었습니다.
- 만들어진 df의 내용을 확인해보면 "A"(firm_id)라는 회사의 날짜(date) 별 주가(price)가 1,2,3,4로 주어져 있습니다.
1. shift() 매서드
이렇게 데이터가 주어졌을때 주가상승률을 계산하려고 합니다. 전년도 주가를 값으로 갖는 price_lag라는 변수를 만들기 위해서 판다스의 shift 매서드를 사용해보겠습니다.
판다스 도큐멘테이션은 여기를 참조해주세요:
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.shift.html
새로운 칼럼 = 기존칼럼.shift(당겨올 칸 수) 의 문법으로 사용할수 있습니다. 예를들면,
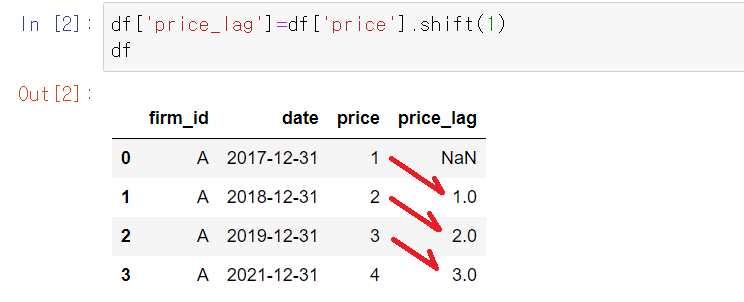
이 코드는 df 안에 'price_lag'라는 새로운 칼럼을 만드는데, 그 값은 df['price']를 한칸씩 당겨오라는 코드입니다.
shift 매소드 안의 1이라는 숫자는 당겨오는 칸 수를 말하는데, 위에서 하나씩 당겨오니 1번 행에는 NaN 값이 뜹니다. 당겨올수 있는 윗 행이 없기 때문입니다.
여기까지 됐으면 아래와 같은 코드를 통해 수익률을 계산할 수 있습니다.

2. (응용) lag operator 만들기
그런데, 데이터 프레임을 살펴보면 문제가 하나있습니다. 날짜가 매년 마지막날로 기입되어있고 연수익률을 구해야 하는데, 2020년 관측치가 없어서 2021년의 return값은 관찰할 수 없는데도 불구하고 기계적으로 한행 씩 위의 값을 가져오다보니 price_L1 값에 2019년 데이터가 들어가있습니다. 물론 return도 잘못계산되어 있습니다.
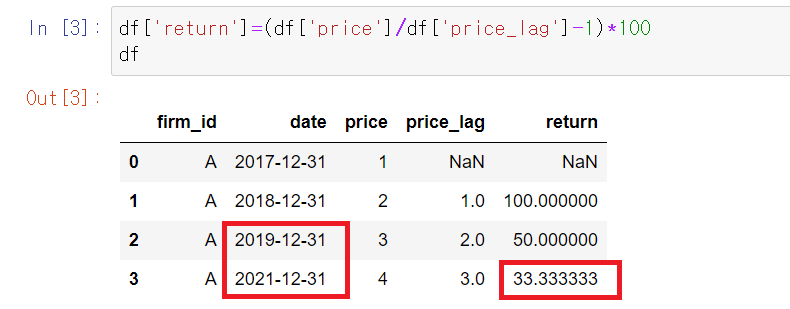
이 문제를 해결하기 위해서 관측시점(date) 사이의 간격을 계산해서, 관측 간격이 1년이 아닌 경우에는 전기값이 nan이 되도록 조정하겠습니다.

#1. 관측시점을 나타내는 date 변수를 다루기 쉽도록 pd.to_datetime을 이용해서 날짜로 인식시켜줍니다.
#2. 데이터를 관측시점으로 정렬합니다. 데이터가 뒤죽박죽 들어가 있어서 잘못된 값을 가져오는걸 방지해줍니다.
(이 단계는 위에서 price_lag를 만들기 전에도 해주면 좋았을 겁니다.)
#3. date의 전기항을 만들어 줍니다. 위에서와 마찬가지로 shift 매서드를 써서 바로 윗 행의 date 값을 가져왔습니다.
#4. 관측시점간 시차를 계산하여 'time_diff'라는 칼럼에 저장해줍니다. 이때 dt.year라는 코드를 이용해서 관측시점의 년도 정보를 추출하였습니다.
#5. time_diff의 값이 1이 아닌 경우, 즉 1년 전의 관측치가 없는 경우, price_lag와 return 값을 nan으로 변환하였습니다.
결과를 보면 2021년의 경우 price_lag 값과 return 값이 결측치 처리된 것을 확인할 수 있습니다.
3. (참고) pct_change
지금까지는 전기값을 불러온 후에 이번기값/전기값 - 1 로 수익률을 계산했는데요, 판다스의 pct_change 매서드를 이용할 수도 있습니다.

df['price'].shift(1) 대신에 df['price'].pct_change()를 해주면 되는데요, 그러면 바로 윗행 값 대비 증가율이 구해집니다.
하지만 이때도 주의할 것은 여전히 바로 윗행 값을 기계적으로 가져오기 때문에 관측치간 시차가 고려되지 않는다는 겁니다. 이 문제는 상기한 방법으로 해결해 주세요.
+ alpha
shift(n)이나 pct_change(n) 안에 양수(n>0)를 쓰면 n만큼 윗행 값을 가져오고 음수(n<0)를 쓰면 n만큼 아래 행 값을 가져와서 연산을 수행합니다.

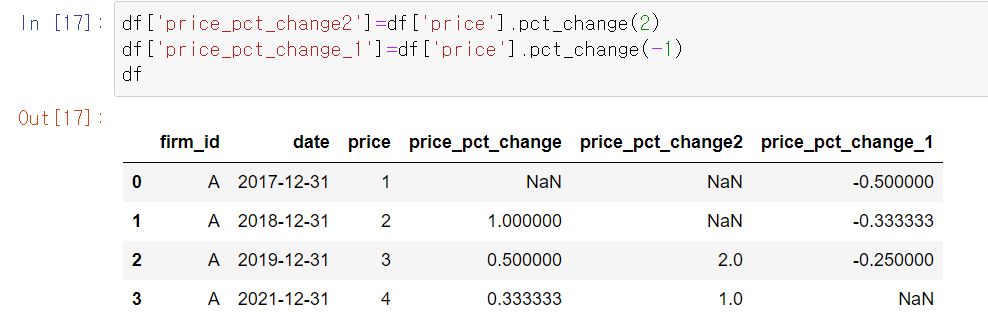
- price_pct_change2 칼럼에서 세번째 행에는 3/1-1=2 , 네번째 행에는 4/2-1=1의 값이 들어가 있습니다.
- price_pct_change_1 칼럼에서 첫째 행에는 1/2-1=-0.5, 두번째 행에는 2/3-1=-0.33333, 세번째 행에는 3/4-1=-0.25 값이 들어갑니다.

'efficiency' 카테고리의 다른 글
| 구글맵 (Google map)으로 여행 지도 만들기- 구글맵 사용법, 공유 방법 (5) | 2024.03.28 |
|---|---|
| 속독 방법 (Speed reading) - 독서, 팀 페리스, 빠르게 읽는 법, 멜버른 여행 도서관 추천 (2) | 2024.02.24 |
| 한글 (HWP) 문서 작성 기본기 - 엑셀 표 한글에 붙여넣기, 자간 줄이기, 단축키 (3) | 2024.01.27 |
| MS Word 수식 빠르게 입력하기 - 그리스 문자, 하첨자/상첨자, 그밖의 표현들 (7) | 2020.03.19 |
| Mendeley - 무료 서지관리 프로그램 Mendeley 사용법 (1) | 2020.03.11 |



